Table of Contents
Comprendre le fonctionnement de Google
Si vous avez un site internet, il est important de comprendre le fonctionnement de Google, cela vous permettra d’analyser votre classement, et donc de pouvoir essayer de l’améliorer. C’est sans doute le plus important conseil SEO. Même s’il existe d’autres moteurs de recherche, comme Bing, Ecosia, ou encore Qwant, c’est réellement Google qu’il faut essayer de comprendre tellement le moteur est dominant en France.
Vous pouvez également retrouver « Tout savoir sur Google », notre petit historique du géant de la tech.
De manière très simpliste, Google est comme une bibliothèque qui recenserait toutes les données – textes, images, vidéos, livres, etc… Google, comme un libraire, redonne les informations demandées par l’utilisateur. C’est la théorie…

De manière générale, Google va avoir deux actions principales :
- Scanner le web – c’est le crawl
- Indexer le web – c’est l’indexation
Le scan – crawl, permet à Google de prendre connaissances des datas qui existent sur internet.
L’indexation permet à Google de trier ses données en fonction de critères qui lui sont propres, pour les restituer à l’utilisateur en fonction de ses recherches.
Le crawl de Google – scanner le web
L’exploration est le processus par lequel Googlebot visite les pages nouvelles et mises à jour pour les ajouter à l’index de Google.
Les robots de Google
Google utilise un énorme ensemble d’ordinateurs pour récupérer (ou « explorer ») des milliards de pages sur le Web. Le programme qui effectue cette recherche est appelé Googlebot (également connu sous le nom de robot, bot ou araignée). Googlebot utilise un processus algorithmique pour déterminer les sites à explorer, la fréquence d’exploration et le nombre de pages à extraire de chaque site.
Le processus d’exploration de Google commence par une liste d’URL de pages Web, générée par les processus d’exploration précédents et complétée par les données Sitemap fournies par les propriétaires de sites Web. Lorsque Googlebot visite une page, il trouve des liens sur la page et les ajoute à sa liste de pages à explorer. Les nouveaux sites, les modifications apportées aux sites existants et les liens morts sont notés et utilisés pour mettre à jour l’index de Google.
Deux manières de scanner le web (primaire et secondaire)
Google utilise deux robots différents pour explorer les sites Web : un robot mobile et un robot de bureau. Chaque type de crawler simule un utilisateur qui visite votre page avec un appareil de ce type.
Google utilise un type d’engin (mobile ou de bureau) comme engin principal pour votre site. Toutes les pages de votre site qui sont explorées par Google le sont à l’aide de l’engin d’exploration principal. Le crawler primaire pour tous les nouveaux sites Web est le crawler mobile.
En outre, Google explore à nouveau quelques pages de votre site avec l’autre type d’engin (mobile ou de bureau). C’est ce qu’on appelle l’exploration secondaire, qui a pour but de déterminer si votre site fonctionne bien avec l’autre type de périphérique.
Google ne va pas scanner tout le site internet
C’est parfois la croix et la bannière pour les consultants SEO comme SEO Inside, mais Google ne pas automatiquement scanner/crawler tout votre site internet. Et c’est frustrant. Parfois c’est souhaitable, et d’autre fois c’est volontaire.
Ainsi:
Les pages bloquées dans le fichier robots.txt ne seront pas explorées, mais elles peuvent être indexées si elles sont liées à une autre page. (Google peut déduire le contenu de la page par un lien pointant vers elle, et indexer la page sans en analyser le contenu).
Google ne peut pas explorer les pages qui ne sont pas accessibles par un utilisateur anonyme. Ainsi, toute protection par login ou autre autorisation empêchera une page d’être explorée.
Les pages qui ont déjà été explorées et qui sont considérées comme des doublons d’une autre page sont explorées moins fréquemment.
Peut-on forcer le crawl de Google ?
En réalité, non. Mais Google a mis en place des outils pour aider le moteur à visiter votre site à nouveau (par exemple si vous avez fait des changements importants):
Soumettre un plan du site (sitemap)
Soumettez des demandes d’exploration pour des pages individuelles.
Utilisez des chemins URL simples, lisibles par l’homme et logiques pour vos pages et fournissez des liens internes clairs et directs au sein du site.
Si vous utilisez des paramètres d’URL sur votre site pour la navigation, par exemple si vous indiquez le pays de l’utilisateur dans un site d’achat international, utilisez l’outil de paramètres d’URL pour indiquer à Google les paramètres importants.
Utilisez le fichier robots.txt à bon escient : Utilisez le fichier robots.txt pour indiquer à Google les pages que vous préférez que Google connaisse ou explore en premier, afin de protéger la charge de votre serveur, et non pour empêcher l’apparition d’éléments dans l’index de Google.
Le concept de « budget crawl« : Budget allouerait un % de son énergie à scanner les sites, et notamment les sites les plus volumineux. Il peut être judicieux, pour ces très gros sites d’aider Google à scanner leurs sites du mieux possible de sorte que Google ne quitte pas le site sans avoir fini son scan. Cette notion peut s’appliquer pour les très gros sites, ce qui n’est pas le cas de 80% du web.
Assurez-vous que Google peut accéder aux pages clés, ainsi qu’aux ressources importantes (images, fichiers CSS, scripts) nécessaires au bon rendu de la page.
Si l’on ne peut pas forcer le scan de votre site, certaines techniques SEO permettent néanmoins de mettre Google sur la bonne voie, comme le maillage internet et le netlinking.
Une fois que Google a scanné le web, il va mettre toutes les informations ainsi collectées dans ses serveurs et algorithmes pour réalisation son indexation. L’indexation est la manière de « ranger » les informations en fonction de la demande faite et de les restituer à l’utilisateur.
C’est entre le crawl et l’indexation que se fait la puissance du SEO.

L’indexation de Google – la classification des données
Analyse des données de votre
Googlebot traite chaque page qu’il explore afin d’en comprendre le contenu. Il traite notamment le contenu textuel, les balises et attributs clés du contenu, tels que les balises <title> et les attributs alt, les images, les vidéos, etc. Googlebot peut traiter de nombreux types de contenu, mais pas tous. Par exemple, nous ne pouvons pas traiter le contenu de certains fichiers rich media.
Entre l’exploration et l’indexation, Google détermine si une page est un doublon ou une copie canonique d’une autre page. Si la page est considérée comme un doublon, elle sera explorée beaucoup moins fréquemment. Les pages similaires sont regroupées dans un document, qui est un groupe d’une ou plusieurs pages comprenant la page canonique (la plus représentative du groupe) et tous les doublons trouvés (qui peuvent être simplement des URL alternatives pour atteindre la même page, ou des versions mobiles ou de bureau alternatives de la même page).
Attention, ce n’est pas parce que Google crawl/scanne votre site qu’il sera automatiquement indexé. Google peut décider que votre site n’est pas assez qualitatif (ou certaines pages de votre site) pour être rendu dans l’index de Google.
Vérifier son indexation
Le moyen le plus simple de le vérifier est de rechercher site:votredomaine.com dans Google. Si Google sait que votre site existe et qu’il l’a déjà exploré, vous verrez une liste de résultats similaire à celle de SEO Inside dans la capture d’écran ci-dessous :
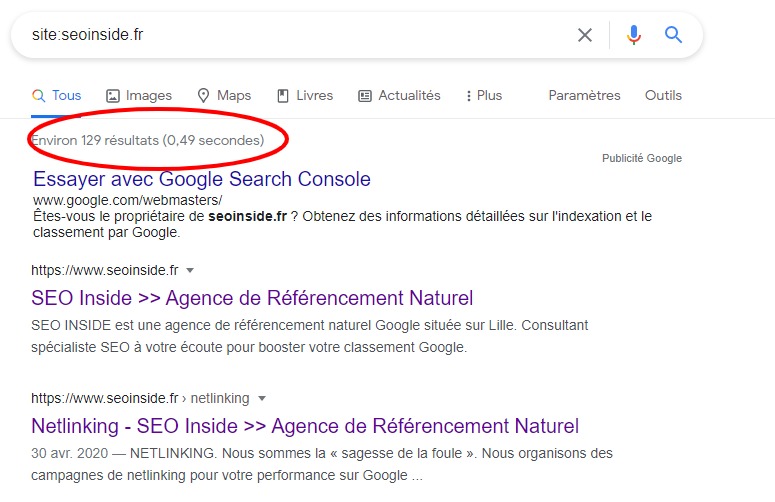
Peut-on forcer l’indexation par Google ?
Certains vous diront que non… On ne peut pas forcer l’indexation de votre site par Google. En réalité c’est possible, mais on ne vous dira pas comment…
Par contre, il est possible d’utiliser les outils de Google à disposition pour essayer de faire indexer le site. A commencer par Google Search Console.
Google Search Console (anciennement connu sous le nom de Google Webmaster Tools) : Elle vous permet de surveiller différents aspects de votre site Web, comme la date de son dernier crawl, les éventuelles erreurs d’indexation, les problèmes de sécurité, etc.
Search Console vous permet également de gérer certains aspects clés de la façon dont vous apparaissez dans les résultats de recherche et de soumettre manuellement des sitemaps.
Améliorer son indexation
Il existe de nombreuses techniques pour améliorer la capacité de Google à comprendre le contenu de votre page :
Empêchez Google d’explorer ou de trouver les pages que vous souhaitez masquer à l’aide de la balise noindex. Ne « noindexez » pas une page qui est bloquée par le fichier robots.txt ; si vous le faites, la balise noindex ne sera pas vue et la page pourrait encore être indexée.
Mais le meilleur moyen d’améliorer son indexation et son classement dans Google est de déliver du contenu de qualité, pertinent, dans un environnement thématique unique, et de manière régulière. C’est pour cela que les agences SEO sont très heureuses…
Si vous avez une question sur ce point, vous pouvez contacter notre agence web SEO à Lille.
--
SEO Inside est une agence web et SEO - en savoir plus sur nous:
Agence web / Audit SEO / Conseil SEO / Création de site internet / Refonte de site internet optimisé pour le SEO / Référencement naturel / Référencement local /Netlinking / Formation SEO / E-Réputation et avis
Voici nos implantations :
Lille / Dunkerque / Amiens – ce sont nos 3 bureaux historiques.
Puis voici nos zones géographiques d’intervention :
Paris / Abbeville / Rouen / Compiègne / Reims / Metz / Caen / Evreux / Nancy / Colmar / Rennes / Le Mans / Orléans / Dijon / Besançon / Angers / Nantes / La Rochelle / Poitiers / Limoges /Clermont-Ferrand / Lyon / Annecy / Grenoble / Valence / Bordeaux / Montauban / Toulouse / Biarritz / Montpellier / Marseille / Cannes / Nice / Avignon / Monaco
SEO INSIDE est une agence web spécialiste en référencement naturel qui se veut proche de vous. Contactez-nous pour discuter de vos projets.