Le SEO a fortement évolué ses 10 dernières années et particulièrement sur la recherche sémantique, à l’initiative des changements d’algorithmes de Google. Bien que les premières applications de la recherche sémantique remontent en fait à 2009, elle s’est accélérée au fil des ans pour finalement créer une révolution dans le fonctionnement des moteurs de recherche. Alors voici un éclairage sur la recherche sémantique.
La recherche sémantique – comment ça marche ?
La recherche sémantique influence toutes les bases du référencement naturel, notamment :
- La recherche de mots-clés
- L’intention de recherche
- la création de contenu
- L’architecture du site
- Les liens internes
- Et plus encore
La recherche sémantique décrit comment Google ne vise pas simplement à fournir des résultats en faisant correspondre des mots clés à la requête de recherche, mais détermine désormais l’intention et la signification de la requête afin de fournir des résultats complets conçus pour :
- répondre exactement à ce que l’utilisateur recherche
- fournir des résultats qui prédisent la prochaine question de l’utilisateur avant même qu’il ne la pose.
[Lire: Comprendre le fonctionnement de Google]
Comment Google gère la sémantique?
Pour y parvenir, Google et les autres moteurs de recherche ont modifié au fil des ans la manière dont ils classent les informations.
Auparavant, Google faisait correspondre une requête de recherche à une page Web en utilisant des facteurs on-page et off-page. Cela signifiait faire correspondre la requête à des mots clés qui apparaissaient à des endroits importants de votre contenu. Vous savez, les balises de titre, les balises H1, le texte d’ancrage, les balises alt et toutes ces optimisations de base du référencement que vous avez apprises.
Il est important de noter que pour Google, la requête de recherche et le contenu n’étaient à l’époque que des chaînes de caractères, ce qui a donné lieu à des stratégies de référencement axées sur les mots clés.
Cela signifie que Google identifiait et classait le contenu en examinant les balises de titre, etc. Une fois que Google a classé le contenu de cette manière, il a pu fournir des résultats de recherche en faisant correspondre le contenu aux mots clés trouvés dans la requête de recherche.
Mais en 2012, Google a introduit Hummingbird qui a été une révolution dans la façon dont les moteurs de recherche catégorisent les informations. En d’autres termes, Google s’est éloigné des chaînes de caractères pour les remplacer par des choses.
[Lire: La définition d’une algorithme]
Cela signifie que Google stocke désormais des informations sur des entités du monde réel (ou des choses) dans une base de données appelée Knowledge Graph. Google dispose également d’informations sur la manière dont ces entités sont liées les unes aux autres. Ce changement de paradigme dans la catégorisation des informations a considérablement modifié les pages de résultats.
Cela signifie qu’une requête de recherche n’est plus une simple chaîne de caractères. Google peut désormais « comprendre » que la chaîne de caractères fait référence à une entité spécifique.
Maintenant que vous avez une vue d’ensemble de base, je dois vous expliquer :
- Ce qu’est le Knowledge Graph de Google
- Ce que sont les entités Google
- Comment Google comprend les relations entre les entités
Qu’est-ce que le Knowledge Graph de Google ?
Le Knowledge Graph de Google est une base de données contenant des informations sur des entités (personnes, lieux et objets). Cette base de données permet à Google de répondre à des questions sur chaque entité et d’afficher ces réponses et les faits associés dans les résultats de recherche.
Google compile ces faits à partir d’un certain nombre de sources différentes, notamment :
- des sources publiques telles que Wikipédia et le World Factbook de la CIA
- Informations autorisées telles que les résultats sportifs et les prévisions météorologiques
- des propriétaires de contenu.
Cependant, il n’est pas utile de disposer d’une grande quantité d’informations si elles ne sont pas classées et structurées. (J’expliquerai comment Google structure ces informations plus loin dans ce billet).
Cela permet à Google de présenter deux types d’informations sur une entité donnée dans les résultats de recherche.
Tout d’abord, Google donne un résumé général du sujet en question. Il peut s’agir d’une définition ou d’un bref résumé de la vie d’une personne célèbre.
Ensuite, en comprenant la relation entre les choses, Google est capable de présenter des informations et des requêtes connexes sur le sujet. Cela permet à l’utilisateur d’explorer le sujet par lui-même.
[Lire: Référencement naturel]
Par exemple: faisons une recherche sur l’acteur Jean Dujardin:
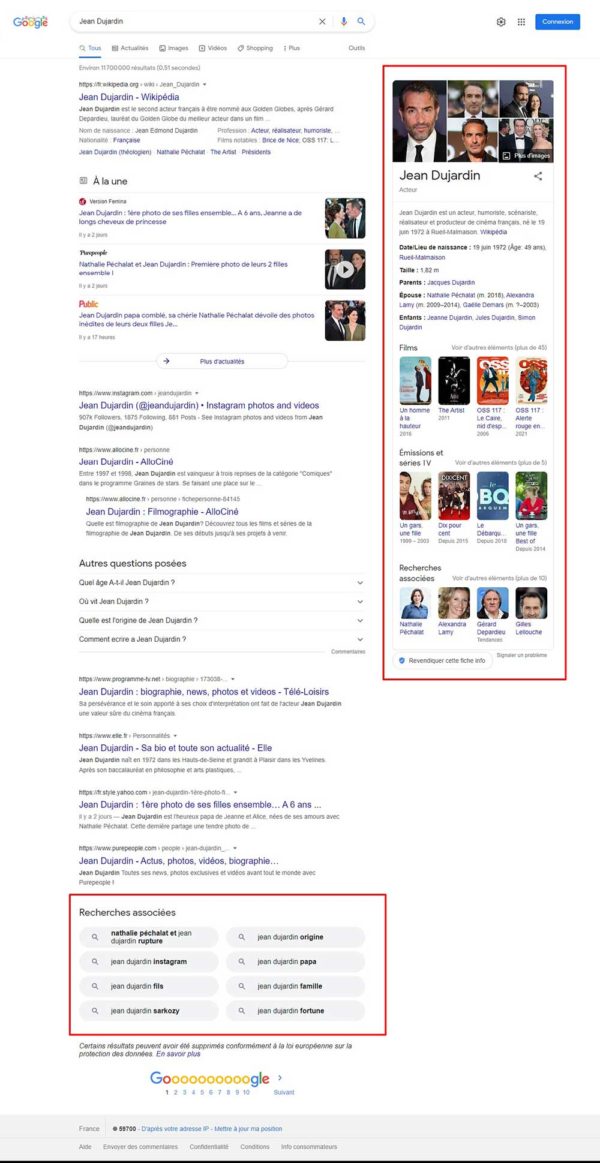
Par exemple, si vous regardez la capture d’écran ci-dessus, vous verrez un Knowledge Graph sur le côté droit de l’écran. La partie supérieure du panneau de connaissances définit qui est Jean Dujardin tout en donnant des informations de base.
Si vous avez compris les informations de base et que vous souhaitez approfondir le sujet, le panneau de connaissances – Knowlege Graph – propose une liste de films, le cadre « Recherches Associées » présente les questions les plus fréquemment posées et la fonction « A La Une » présente les actualités.
En ajoutant toutes ces options, Google incite l’utilisateur à explorer davantage d’informations sur l’entité.
Après avoir exploré le Knowledge Graph, nous allons maintenant comprendre ce que sont les entités.
Que sont les entités Google ?
Google définit les entités comme « une chose ou un concept singulier, unique, bien défini et distinct ».
Bien que nous puissions imaginer qu’une entité fait référence à un objet, selon la définition de Google, une entité pourrait tout aussi bien faire référence à quelque chose d’abstrait comme un concept. Mais, pour être définies comme une entité, elles sont représentées linguistiquement par des noms. En d’autres termes, une entité est une chose qui peut être identifiée, classée et catégorisée.
Cela signifie que même les couleurs, les sentiments ou les idées peuvent être des entités.
Pour « comprendre » réellement ces entités, Google doit leur donner un contexte en leur attribuant des attributs.
Par exemple, une requête pour « apple » (en anglais: pomme) est ambiguë pour Google. Sur quelle entité le chercheur cherche-t-il des informations ? Cherche-t-il des résultats sur le fruit ou sur l’entreprise Apple ?
En classant une entité comme un type de fruit et une autre comme une marque qui vend des appareils, Google est capable de classer les pommes de deux manières différentes et donc de répondre à deux intentions de recherche complètement différentes avec deux entités différentes.
Le Knowledge Graph de Google ne se contente pas d’attribuer des attributs aux entités pour les définir comme uniques. Google utilise également ces attributs pour « comprendre » comment ces entités sont interconnectées. Les entités possédant des attributs similaires sont regroupées.
En d’autres termes, les pommes, les oranges et les poires sont toutes regroupées sous le terme de « fruits ».
En outre, le Knowledge Graph de Google regroupe également les entités en thèmes et est capable de comprendre que les thèmes existent dans une structure hiérarchique de thèmes et de sous-thèmes.
Google appelle cela la couche des sujets – Topical Layer (en anglais).
La couche de sujets permet à Google d’ajouter dynamiquement des onglets de sous-sujets à ses panneaux de connaissances, transformant ainsi l’expérience de recherche d’une recherche unique en un parcours qui peut potentiellement conduire un chercheur à travers un sujet entier.
Par exemple, si vous effectuez une recherche sur le thème général « l’univers », vous recherchez peut-être des informations générales. Mais, une fois que vous avez trouvé ce que vous cherchiez, vous pouvez vouloir approfondir le sujet.
Google vous aide en ajoutant des sous-thèmes au panneau de connaissances. Au final, vous obtenez des incitations à découvrir plus d’informations par des recherches associées, mais aussi des news à la une, des vidéos, etc…
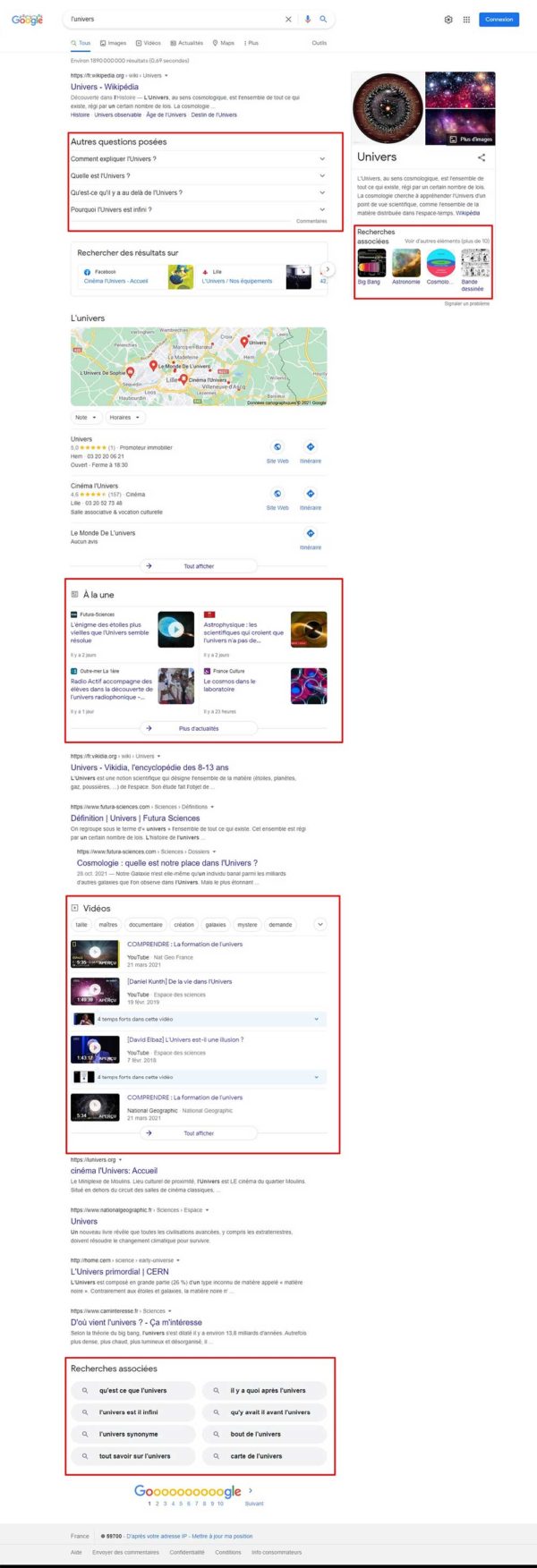
Une recherche sur l’univers vous entraine aussi à découvrir Le Big Bang, l’Astronomie, la Cosmologie… des thématiques suggérées dans la boite Knowledge Graph de droite.
Cela nous montre que Google est capable non seulement de regrouper des entités par le biais d’attributs partagés, mais aussi de comprendre comment elles existent dans une hiérarchie de sujets et de sous-thèmes.
Une fois que nous avons compris ce que sont les entités, examinons de plus près la façon dont les moteurs de recherche comprennent leurs relations. Quelle est l’anatomie des informations dans le graphique de connaissances de Google ?
Eh bien, tout cela nous amène aux triples.
Qu’est-ce qu’un triple ?
Un triple fait référence à la relation entre deux entités. Ces relations existent en tant qu’informations dans le graphe de connaissances qui est structuré en utilisant une structure sujet-prédicat-objet.
En termes simples, le sujet et l’objet sont des entités. Le prédicat décrit la relation entre ces deux entités.
Ainsi, par exemple, si nous examinons la phrase « Jean aime la musique ».
La phrase est composée de :
Un sujet : Jean
Un prédicat : Aime
Un objet : Musique
Dans cet exemple, le sujet et l’objet sont tous deux des entités. Le mot « aime » décrit la relation entre les entités.
En allant plus loin, l’objet de notre triple « musique » pourrait être le sujet d’un autre triple.
Ainsi, la phrase ‘La musique est une forme d’art’ utilise l’entité ‘musique’ qui apparaissait comme objet dans la dernière phrase ‘Jean aime la musique’. Cependant, cette entité est maintenant un sujet dans cette nouvelle phrase.
En reliant les entités de cette manière, Google a relié trois entités entre elles. En stockant les informations de cette manière, Google relie littéralement des millions d’entités entre elles.
En comprenant ce concept, vous disposez de l’une des bases du référencement sémantique.
[Lire: Comment développer une stratégie SEO / de référencement naturel]
Qu’est-ce qui se passe quand on recherche sur Google
Nous avons donc abordé quelques concepts de base pour comprendre la recherche sémantique. Maintenant, mettons tout en commun en examinant ce qui se passe réellement lorsqu’une personne effectue une recherche sur Google.
Pour cela, nous devons comprendre comment Google traite les requêtes de recherche, car c’est la première étape pour que Google affiche des résultats dans les pages de résultats.
Comprendre les requêtes de recherche
Pour qu’un moteur de recherche puisse fournir des résultats complets qui correspondent étroitement à l’intention de l’utilisateur et l’emmener dans un voyage de découverte, Google doit comprendre ce que l’utilisateur recherche lorsqu’il tape une requête dans son navigateur.
Pour ce faire, Google doit essayer de comprendre le sens sous-jacent de la requête de l’internaute.
Ce n’est toutefois pas si facile à réaliser. En tant que personnes, nous avons tendance à trouver de nombreuses façons de dire la même chose, et formuler une question de différentes manières peut souvent créer des significations légèrement différentes.
De plus, il est important de comprendre que Google n’est pas capable de comprendre le langage comme un être humain. En d’autres termes, Google ne peut pas (encore) comprendre l’intention de l’utilisateur à partir de la structure des phrases et de la linguistique.
En revanche, Google est capable d’examiner sa base de données d’entités et leurs relations et de comprendre ce que recherche un internaute.
Par exemple, tapez ces deux recherches différentes dans Google :
- qui sont les membres du groupe Indochine ?
- membres d’Indochine
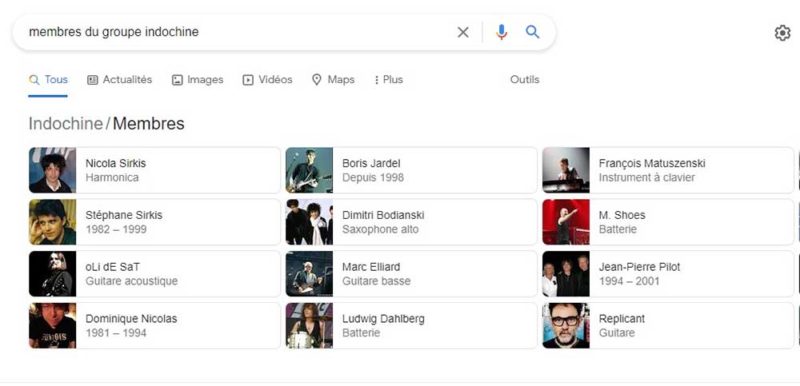
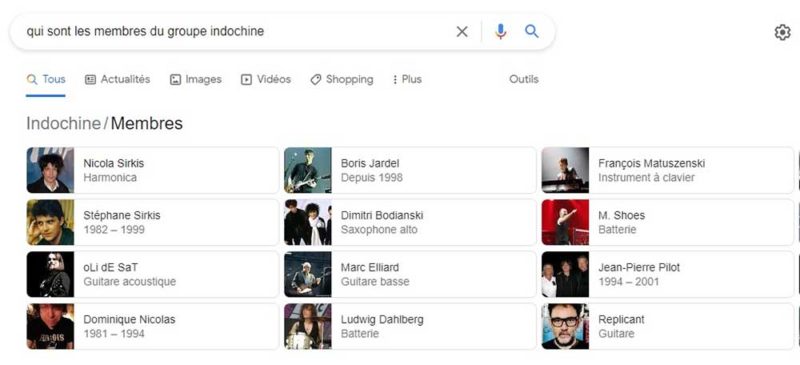
Si vous l’avez fait, vous remarquerez que les deux requêtes ont donné des résultats similaires, même si l’une était formulée comme une question et l’autre comme une question implicite. La raison en est que Google est capable de comprendre l’entité « Indochine ». Google comprend également que cette entité est associée à d’autres entités.
L’entité Nicolas Sirkis, par exemple, est étroitement liée à l’entité Indochine.
Qui plus est, cette relation est définie comme un « membre ».
Grâce à cette relation dans sa base de données, Google traite les deux requêtes de la même manière, même si l’une d’entre elles comprend les mots « qui sont » alors que l’autre se contente de nommer l’entité Indochine et d’y joindre le mot « membres ».
L’utilisateur recherche ces entités étroitement liées définies comme des « membres ». Google peut alors proposer des résultats basés sur sa « compréhension » de la requête.
Mais que se passe-t-il si Google ne « comprend » pas la requête ? Que se passe-t-il si la base de données de Google ne contient pas les entités sur lesquelles porte la requête, ou si la base de données ne comprend pas le lien entre les entités ?
Dans de tels cas, Google s’appuie sur des algorithmes comme Rank Brain pour imiter la compréhension sémantique.
Pour ce faire, Rank Brain utilise une base de données de requêtes similaires et se contente de deviner.
Cela peut parfois donner lieu à des intentions de recherche multiples sur une SERP.
Pourquoi la recherche sémantique
Tout cela soulève la question suivante : pourquoi Google fonctionne de cette manière ? Je veux dire qu’il semble que Google ait inventé la bibliothèque la plus sophistiquée du monde.
La réponse est qu’en comprenant les entités et leurs relations, Google est en mesure d’offrir une expérience utilisateur exceptionnelle. En se basant sur les données de Google, il est capable de présenter un sujet de haut en bas. Cela signifie que lorsqu’un internaute effectue une recherche sur un sujet, Google est en mesure de lui fournir les informations qu’il recherchait et de prédire ce qu’il souhaite savoir ensuite.
Pour ce faire, Google présente des intentions d’utilisateur étroitement liées dans une SERP donnée. Ainsi, une fois que l’utilisateur a obtenu ce qu’il cherchait, de nouvelles questions peuvent surgir dans son esprit. En d’autres termes, la question initiale se transforme en un voyage de découverte, qui donne lieu à de nombreuses recherches.
Cela permet à Google de maximiser le temps passé sur le moteur de recherche, et d’apporter une expérience optimale pour l’utilisateur qui ne cherchera donc pas à changer de moteur de recherche. Car sur chaque haut de page de Google se trouve aussi la publicité, le nerf de la guerre…
SEO INSIDE est une agence SEO.
--
SEO Inside est une agence web et SEO - en savoir plus sur nous:
Agence web / Audit SEO / Conseil SEO / Création de site internet / Refonte de site internet optimisé pour le SEO / Référencement naturel / Référencement local /Netlinking / Formation SEO / E-Réputation et avis
Voici nos implantations :
Lille / Dunkerque / Amiens – ce sont nos 3 bureaux historiques.
Puis voici nos zones géographiques d’intervention :
Paris / Abbeville / Rouen / Compiègne / Reims / Metz / Caen / Evreux / Nancy / Colmar / Rennes / Le Mans / Orléans / Dijon / Besançon / Angers / Nantes / La Rochelle / Poitiers / Limoges /Clermont-Ferrand / Lyon / Annecy / Grenoble / Valence / Bordeaux / Montauban / Toulouse / Biarritz / Montpellier / Marseille / Cannes / Nice / Avignon / Monaco
SEO INSIDE est une agence web spécialiste en référencement naturel qui se veut proche de vous. Contactez-nous pour discuter de vos projets.